diff --git a/training-code/Lndian_Language_to_Indian_Language_Machine_Transaltion_IIITH_2023_v1_5.ipynb b/training-code/Lndian_Language_to_Indian_Language_Machine_Transaltion_IIITH_2023_v1_5.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..cfb96a06c913d063919fa7129b77c703292b3208
--- /dev/null
+++ b/training-code/Lndian_Language_to_Indian_Language_Machine_Transaltion_IIITH_2023_v1_5.ipynb
@@ -0,0 +1,976 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# ** Hybrid Neural Machine Translation for HimangiY **\n",
+ "#### Vandan Mujadia, Dipti Misra Sharma\n",
+ "#### LTRC, IIIT-Hyderabad, Hyderabad"
+ ],
+ "metadata": {
+ "id": "axRPPFFocszE"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "This demonstrates how to train a sequence-to-sequence (seq2seq) model for Kannada-to-Hindi translation **roughly** based on [Effective Approaches to Attention-based Neural Machine Translation](https://arxiv.org/abs/1706.03762) (Vaswani, Ashish et al).\n",
+ "\n",
+ "## An Example to Understand sequence to Sequence processing using Transformar Network.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Source: [Google AI Blog](https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html)\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "aX4IVQ5qf52I"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Applying the Transformer to machine translation.\n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Source: [Google AI Blog](https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html)\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "aX4IVQ5qf52I"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Applying the Transformer to machine translation.\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " \n",
+ "  \n",
+ " \n",
+ " | \n",
+ "
\n",
+ "\n",
+ " | This tutorial: An encoder/decoder connected by self attention neural network. | \n",
+ "
\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "J36LSLbtf_Co"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Tools that we are using here\n",
+ "\n",
+ "* Library : Opennmt\n",
+ "* Library : pytorch based neural network implemtation\n"
+ ],
+ "metadata": {
+ "id": "z7BlcJtET3DH"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "gknS9QN5aU7P",
+ "outputId": "6be0aaa1-df1c-4ee1-f9e8-8ac70db99fa4"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Requirement already satisfied: pip in /usr/local/lib/python3.10/dist-packages (23.1.2)\n",
+ "Collecting pip\n",
+ " Downloading pip-23.2.1-py3-none-any.whl (2.1 MB)\n",
+ "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m2.1/2.1 MB\u001b[0m \u001b[31m20.9 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
+ "\u001b[?25hInstalling collected packages: pip\n",
+ " Attempting uninstall: pip\n",
+ " Found existing installation: pip 23.1.2\n",
+ " Uninstalling pip-23.1.2:\n",
+ " Successfully uninstalled pip-23.1.2\n",
+ "Successfully installed pip-23.2.1\n",
+ "OpenNMT-py sample_data\n",
+ "/content/OpenNMT-py\n",
+ "Note: switching to '1.2.0'.\n",
+ "\n",
+ "You are in 'detached HEAD' state. You can look around, make experimental\n",
+ "changes and commit them, and you can discard any commits you make in this\n",
+ "state without impacting any branches by switching back to a branch.\n",
+ "\n",
+ "If you want to create a new branch to retain commits you create, you may\n",
+ "do so (now or later) by using -c with the switch command. Example:\n",
+ "\n",
+ " git switch -c \n",
+ "\n",
+ "Or undo this operation with:\n",
+ "\n",
+ " git switch -\n",
+ "\n",
+ "Turn off this advice by setting config variable advice.detachedHead to false\n",
+ "\n",
+ "HEAD is now at 60125c80 Bump v1.2.0 (#1850)\n",
+ "Collecting torchtext==0.4.0\n",
+ " Downloading torchtext-0.4.0-py3-none-any.whl (53 kB)\n",
+ "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m53.1/53.1 kB\u001b[0m \u001b[31m1.5 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
+ "\u001b[?25hCollecting torch==1.11.0\n",
+ " Downloading torch-1.11.0-cp310-cp310-manylinux1_x86_64.whl (750.6 MB)\n",
+ "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m750.6/750.6 MB\u001b[0m \u001b[31m1.7 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
+ "\u001b[?25hRequirement already satisfied: tqdm in /usr/local/lib/python3.10/dist-packages (from torchtext==0.4.0) (4.66.1)\n",
+ "Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from torchtext==0.4.0) (2.31.0)\n",
+ "Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from torchtext==0.4.0) (1.23.5)\n",
+ "Requirement already satisfied: six in /usr/local/lib/python3.10/dist-packages (from torchtext==0.4.0) (1.16.0)\n",
+ "Requirement already satisfied: typing-extensions in /usr/local/lib/python3.10/dist-packages (from torch==1.11.0) (4.5.0)\n",
+ "Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->torchtext==0.4.0) (3.2.0)\n",
+ "Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->torchtext==0.4.0) (3.4)\n",
+ "Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->torchtext==0.4.0) (2.0.4)\n",
+ "Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->torchtext==0.4.0) (2023.7.22)\n",
+ "Installing collected packages: torch, torchtext\n",
+ " Attempting uninstall: torch\n",
+ " Found existing installation: torch 2.0.1+cu118\n",
+ " Uninstalling torch-2.0.1+cu118:\n",
+ " Successfully uninstalled torch-2.0.1+cu118\n",
+ " Attempting uninstall: torchtext\n",
+ " Found existing installation: torchtext 0.15.2\n",
+ " Uninstalling torchtext-0.15.2:\n",
+ " Successfully uninstalled torchtext-0.15.2\n",
+ "\u001b[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\n",
+ "torchaudio 2.0.2+cu118 requires torch==2.0.1, but you have torch 1.11.0 which is incompatible.\n",
+ "torchdata 0.6.1 requires torch==2.0.1, but you have torch 1.11.0 which is incompatible.\n",
+ "torchvision 0.15.2+cu118 requires torch==2.0.1, but you have torch 1.11.0 which is incompatible.\u001b[0m\u001b[31m\n",
+ "\u001b[0mSuccessfully installed torch-1.11.0 torchtext-0.4.0\n",
+ "\u001b[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\u001b[0m\u001b[33m\n",
+ "\u001b[0m"
+ ]
+ }
+ ],
+ "source": [
+ "!pip install -U pip\n",
+ "!!git clone https://github.com/OpenNMT/OpenNMT-py\n",
+ "! ls\n",
+ "%cd OpenNMT-py\n",
+ "!git checkout 1.2.0\n",
+ "!pip3 install torchtext==0.4.0 torch==1.11.0"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "%cd /content/"
+ ],
+ "metadata": {
+ "id": "_ZlqbvXSUi9h",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "12ceaba9-6468-414d-9621-a66a0ecec700"
+ },
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "/content\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Check GPU"
+ ],
+ "metadata": {
+ "id": "t0jUxSkJTpCY"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "j6W53TaterZ4",
+ "outputId": "44489711-32d8-45fe-82a1-18fe11eb003d"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "/bin/bash: line 1: nvidia-smi: command not found\n"
+ ]
+ }
+ ],
+ "source": [
+ "!nvidia-smi"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Tokenizer Tool"
+ ],
+ "metadata": {
+ "id": "mCO9U93FVy74"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "0RXkfYjYL35Q",
+ "outputId": "90c6e87d-f371-4e74-8d3b-edebe5e7fdad"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Collecting git+https://github.com/vmujadia/tokenizer.git\n",
+ " Cloning https://github.com/vmujadia/tokenizer.git to /tmp/pip-req-build-3lao7iuu\n",
+ " Running command git clone --filter=blob:none --quiet https://github.com/vmujadia/tokenizer.git /tmp/pip-req-build-3lao7iuu\n",
+ " Resolved https://github.com/vmujadia/tokenizer.git to commit 93cd09b81702108a51c08c9796fd1cc941a1b98b\n",
+ " Preparing metadata (setup.py) ... \u001b[?25l\u001b[?25hdone\n",
+ "Requirement already satisfied: pyyaml in /usr/local/lib/python3.10/dist-packages (from IL-Tokenizer==0.0.2) (6.0.1)\n",
+ "Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from IL-Tokenizer==0.0.2) (2.31.0)\n",
+ "Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->IL-Tokenizer==0.0.2) (3.2.0)\n",
+ "Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->IL-Tokenizer==0.0.2) (3.4)\n",
+ "Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->IL-Tokenizer==0.0.2) (2.0.4)\n",
+ "Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->IL-Tokenizer==0.0.2) (2023.7.22)\n",
+ "Building wheels for collected packages: IL-Tokenizer\n",
+ " Building wheel for IL-Tokenizer (setup.py) ... \u001b[?25l\u001b[?25hdone\n",
+ " Created wheel for IL-Tokenizer: filename=IL_Tokenizer-0.0.2-py3-none-any.whl size=7225 sha256=1bec4df8b3d0a8ca3a48367f72deb4b2d68623a782699f27934083cfbaa6b959\n",
+ " Stored in directory: /tmp/pip-ephem-wheel-cache-624d680m/wheels/9a/fb/5b/3d75bfde8561726121c09f0f0a83389c05312df8a513808c41\n",
+ "Successfully built IL-Tokenizer\n",
+ "Installing collected packages: IL-Tokenizer\n",
+ "Successfully installed IL-Tokenizer-0.0.2\n",
+ "\u001b[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\u001b[0m\u001b[33m\n",
+ "\u001b[0m"
+ ]
+ }
+ ],
+ "source": [
+ "!pip install git+https://github.com/vmujadia/tokenizer.git --upgrade"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# To Clean and Filter Parallel Corpora"
+ ],
+ "metadata": {
+ "id": "GDJjJCnEV9Cx"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "gtF7MxJdMeky",
+ "outputId": "c3cb0732-7722-44c3-bc64-bb5de6c5de52"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Cloning into 'mosesdecoder'...\n",
+ "remote: Enumerating objects: 148097, done.\u001b[K\n",
+ "remote: Counting objects: 100% (525/525), done.\u001b[K\n",
+ "remote: Compressing objects: 100% (229/229), done.\u001b[K\n",
+ "remote: Total 148097 (delta 323), reused 441 (delta 292), pack-reused 147572\u001b[K\n",
+ "Receiving objects: 100% (148097/148097), 129.88 MiB | 10.32 MiB/s, done.\n",
+ "Resolving deltas: 100% (114349/114349), done.\n"
+ ]
+ }
+ ],
+ "source": [
+ "!git clone https://github.com/moses-smt/mosesdecoder.git"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# To tackle vocabulary issue : Subword algorithm"
+ ],
+ "metadata": {
+ "id": "XksbkTQ9VUaQ"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "KGWYp4kFLUYL",
+ "outputId": "9cd5fc2b-9909-4bfb-a25d-fbb296e32281"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Cloning into 'subword-nmt'...\n",
+ "remote: Enumerating objects: 597, done.\u001b[K\n",
+ "remote: Counting objects: 100% (21/21), done.\u001b[K\n",
+ "remote: Compressing objects: 100% (17/17), done.\u001b[K\n",
+ "remote: Total 597 (delta 8), reused 12 (delta 4), pack-reused 576\u001b[K\n",
+ "Receiving objects: 100% (597/597), 252.23 KiB | 3.11 MiB/s, done.\n",
+ "Resolving deltas: 100% (357/357), done.\n"
+ ]
+ }
+ ],
+ "source": [
+ "!git clone https://github.com/rsennrich/subword-nmt.git"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "cC4xAujyMiYH",
+ "outputId": "87e6da6b-cea1-46dd-a89d-4d23459df3f0"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "mosesdecoder/scripts/training/clean-corpus-n.perl\n"
+ ]
+ }
+ ],
+ "source": [
+ "!ls mosesdecoder/scripts/training/clean-corpus-n.perl"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# For this; Training Corpora\n",
+ "\n",
+ "## Kannada - Hindi\n",
+ "## (small courpus MIT+CDAC-B developed)"
+ ],
+ "metadata": {
+ "id": "RAMhRFrfZBGx"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "roXS-U5oM_A4",
+ "outputId": "6c8d82b9-b196-4bd3-8325-e0145a43f7cb"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "--2023-09-23 05:22:08-- https://ssmt.iiit.ac.in/uploads/data_mining/kannada-hindi_combined_all.hi\n",
+ "Resolving ssmt.iiit.ac.in (ssmt.iiit.ac.in)... 196.12.53.52\n",
+ "Connecting to ssmt.iiit.ac.in (ssmt.iiit.ac.in)|196.12.53.52|:443... connected.\n",
+ "HTTP request sent, awaiting response... 200 OK\n",
+ "Length: 4195974 (4.0M) [application/octet-stream]\n",
+ "Saving to: ‘train.src’\n",
+ "\n",
+ "train.src 100%[===================>] 4.00M 460KB/s in 8.0s \n",
+ "\n",
+ "2023-09-23 05:22:18 (515 KB/s) - ‘train.src’ saved [4195974/4195974]\n",
+ "\n",
+ "--2023-09-23 05:22:18-- https://ssmt.iiit.ac.in/uploads/data_mining/kannada-hindi_combined_all.kn\n",
+ "Resolving ssmt.iiit.ac.in (ssmt.iiit.ac.in)... 196.12.53.52\n",
+ "Connecting to ssmt.iiit.ac.in (ssmt.iiit.ac.in)|196.12.53.52|:443... connected.\n",
+ "HTTP request sent, awaiting response... 200 OK\n",
+ "Length: 3796364 (3.6M) [application/octet-stream]\n",
+ "Saving to: ‘train.tgt’\n",
+ "\n",
+ "train.tgt 100%[===================>] 3.62M 1.03MB/s in 3.5s \n",
+ "\n",
+ "2023-09-23 05:22:23 (1.03 MB/s) - ‘train.tgt’ saved [3796364/3796364]\n",
+ "\n",
+ "--2023-09-23 05:22:23-- https://ssmt.iiit.ac.in/uploads/data_mining/flores200-dev.hi\n",
+ "Resolving ssmt.iiit.ac.in (ssmt.iiit.ac.in)... 196.12.53.52\n",
+ "Connecting to ssmt.iiit.ac.in (ssmt.iiit.ac.in)|196.12.53.52|:443... connected.\n",
+ "HTTP request sent, awaiting response... 200 OK\n",
+ "Length: 323267 (316K) [application/octet-stream]\n",
+ "Saving to: ‘valid.src’\n",
+ "\n",
+ "valid.src 100%[===================>] 315.69K 287KB/s in 1.1s \n",
+ "\n",
+ "2023-09-23 05:22:25 (287 KB/s) - ‘valid.src’ saved [323267/323267]\n",
+ "\n",
+ "--2023-09-23 05:22:25-- https://ssmt.iiit.ac.in/uploads/data_mining/flores200-dev.kn\n",
+ "Resolving ssmt.iiit.ac.in (ssmt.iiit.ac.in)... 196.12.53.52\n",
+ "Connecting to ssmt.iiit.ac.in (ssmt.iiit.ac.in)|196.12.53.52|:443... connected.\n",
+ "HTTP request sent, awaiting response... 200 OK\n",
+ "Length: 358653 (350K) [application/octet-stream]\n",
+ "Saving to: ‘valid.tgt’\n",
+ "\n",
+ "valid.tgt 100%[===================>] 350.25K 59.0KB/s in 5.9s \n",
+ "\n",
+ "2023-09-23 05:22:33 (59.0 KB/s) - ‘valid.tgt’ saved [358653/358653]\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "! wget -O train.src https://ssmt.iiit.ac.in/uploads/data_mining/kannada-hindi_combined_all.hi\n",
+ "! wget -O train.tgt https://ssmt.iiit.ac.in/uploads/data_mining/kannada-hindi_combined_all.kn\n",
+ "! wget -O valid.src https://ssmt.iiit.ac.in/uploads/data_mining/flores200-dev.hi\n",
+ "! wget -O valid.tgt https://ssmt.iiit.ac.in/uploads/data_mining/flores200-dev.kn"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Data Numbers"
+ ],
+ "metadata": {
+ "id": "plXXn4vYh7dL"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "FnRRGSCnQ8DI",
+ "outputId": "e461d175-8340-4724-d30d-32ee541a6556"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Data Stats\n",
+ " 15877 train.src\n",
+ " 15877 train.tgt\n",
+ " 31754 total\n",
+ " 997 valid.src\n",
+ " 997 valid.tgt\n",
+ " 1994 total\n"
+ ]
+ }
+ ],
+ "source": [
+ "print ('Data Stats')\n",
+ "! wc -l train.*\n",
+ "! wc -l valid.*"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Tokenize the text"
+ ],
+ "metadata": {
+ "id": "fXbHzLYYiCvZ"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "lbWZ1WpJPR1R"
+ },
+ "outputs": [],
+ "source": [
+ "from ilstokenizer import tokenizer\n",
+ "import codecs\n",
+ "\n",
+ "def to_tokenize_and_lower(input_path, output_path):\n",
+ " outfile = open(output_path, 'w')\n",
+ " for line in codecs.open(input_path):\n",
+ " line = line.strip()\n",
+ " line = tokenizer.tokenize(line).lower()\n",
+ " #print (line)\n",
+ " outfile.write(line+'\\n')\n",
+ " outfile.close()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "fjtXoUVZQXk4"
+ },
+ "outputs": [],
+ "source": [
+ "to_tokenize_and_lower('train.src','train.src.tkn')\n",
+ "to_tokenize_and_lower('train.tgt','train.tgt.tkn')\n",
+ "\n",
+ "to_tokenize_and_lower('valid.src','valid.src.tkn')\n",
+ "to_tokenize_and_lower('valid.tgt','valid.tgt.tkn')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Lzgo8VWmNYAG"
+ },
+ "outputs": [],
+ "source": [
+ "! cat train.src.tkn > train.all.tkn\n",
+ "! cat train.tgt.tkn >> train.all.tkn"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Data Cleaning"
+ ],
+ "metadata": {
+ "id": "FWpmi90piKUC"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "JBSq7A5gRuux",
+ "outputId": "bb481b2a-0b25-47e4-93c0-e304fa9a96fa"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "clean-corpus.perl: processing train.src.tkn & .tgt.tkn to train_filtered, cutoff 1-250, ratio 2.5\n",
+ ".\n",
+ "Input sentences: 15878 Output sentences: 15807\n"
+ ]
+ }
+ ],
+ "source": [
+ "! perl mosesdecoder/scripts/training/clean-corpus-n.perl -ratio 2.5 train src.tkn tgt.tkn train_filtered 1 250"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "D2ibyHwUSkrL",
+ "outputId": "4c64d163-dca5-40ad-8f9f-c75227df72e1"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Data Stats\n",
+ " 31756 train.all.tkn\n",
+ " 15807 train_filtered.src.tkn\n",
+ " 15807 train_filtered.tgt.tkn\n",
+ " 15877 train.src\n",
+ " 15878 train.src.tkn\n",
+ " 15877 train.tgt\n",
+ " 15878 train.tgt.tkn\n",
+ " 126880 total\n",
+ " 997 valid.src\n",
+ " 997 valid.src.tkn\n",
+ " 997 valid.tgt\n",
+ " 997 valid.tgt.tkn\n",
+ " 3988 total\n"
+ ]
+ }
+ ],
+ "source": [
+ "print ('Data Stats')\n",
+ "! wc -l train*\n",
+ "! wc -l valid*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "print ('Data Stats')\n",
+ "! wc -l train*\n",
+ "! wc -l valid*"
+ ],
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "CPGS3qLW6o9d",
+ "outputId": "d9f5dd94-8d37-4cde-c7a6-77854dc4cc55"
+ },
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Data Stats\n",
+ " 31756 train.all.tkn\n",
+ " 15807 train_filtered.src.tkn\n",
+ " 15807 train_filtered.src.tkn.pos\n",
+ " 15807 train_filtered.src.tkn.posword\n",
+ " 15807 train_filtered.tgt.tkn\n",
+ " 15877 train.src\n",
+ " 15878 train.src.tkn\n",
+ " 15877 train.tgt\n",
+ " 15878 train.tgt.tkn\n",
+ " 158494 total\n",
+ " 997 valid.src\n",
+ " 997 valid.src.tkn\n",
+ " 997 valid.tgt\n",
+ " 997 valid.tgt.tkn\n",
+ " 3988 total\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Train subword model,\n",
+ "## Experiment with no of subword merge operation"
+ ],
+ "metadata": {
+ "id": "oukoeGHniPEC"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "COV2XMvATTIw",
+ "outputId": "f020da54-a4a4-4d35-fbdc-9a6c343da6af"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "100% 5000/5000 [00:23<00:00, 211.36it/s]\n"
+ ]
+ }
+ ],
+ "source": [
+ "!python subword-nmt/subword_nmt/learn_bpe.py -s 5000 < train.all.tkn > train.codes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# How do subword codes look"
+ ],
+ "metadata": {
+ "id": "4AZodBXIir_D"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "3kduoQxrOwc7",
+ "outputId": "b001f507-dcb4-4c13-a019-dfb6d74d1a3b"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "#version: 0.2\n",
+ "ತ ್\n",
+ "ನ ್\n",
+ "क े\n",
+ "ಲ ್\n",
+ "् र\n",
+ "ಾ ಗ\n",
+ "ಗ ಳ\n",
+ "ತ್ ತ\n",
+ "ಕ ್\n"
+ ]
+ }
+ ],
+ "source": [
+ "! head -n 10 train.codes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Apply Subword to the corpus"
+ ],
+ "metadata": {
+ "id": "eSbwhzpqjbH8"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "13QghGSZT6tA"
+ },
+ "outputs": [],
+ "source": [
+ "!python subword-nmt/subword_nmt/apply_bpe.py -c train.codes < train.src > train.kn\n",
+ "!python subword-nmt/subword_nmt/apply_bpe.py -c train.codes < train.tgt > train.hi\n",
+ "\n",
+ "!python subword-nmt/subword_nmt/apply_bpe.py -c train.codes < valid.src > valid.kn\n",
+ "!python subword-nmt/subword_nmt/apply_bpe.py -c train.codes < valid.tgt > valid.hi"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Training Corpus now"
+ ],
+ "metadata": {
+ "id": "YOo9h4ULjXuU"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "_CRKB3qOURoT",
+ "outputId": "2229679e-b3c0-4110-d2f8-abde21f06bff"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "ಪ್ರ@@ ವಾ@@ ಹ ಪೀ@@ ಡಿತ ಕ@@ ಲ್ಲ@@ ಿದ್ದ@@ ಲು ಗಣ@@ ಿಗಳನ್ನು s@@ e@@ c@@ l ಕೈ@@ ಬಿಡ@@ ಬೇಕಾ@@ ಯಿತು .\n",
+ "ಹಣಕಾ@@ ಸು ಸಚಿ@@ ವಾ@@ ಲಯ@@ ವು ರಾಯ@@ ಧ@@ ನ ಮೇಲಿನ ತನ್ನ ಕೈ@@ ಬಿ@@ ಟ್ಟ ಹಕ್ಕ@@ ನ್ನು ಹೊ@@ ಸದ@@ ಾಗಿ ಪ್ರಸ್ತು@@ ತ@@ ಪಡಿಸಲು ನಿರ್ಧರಿಸ@@ ಿದೆ .\n",
+ "ಕಂಪ@@ ನಿಯ ತೊ@@ ರೆ@@ ದ ಆ@@ ಸ್@@ ತಿಯನ್ನು ಹ@@ ರಾಜ@@ ು ಮಾಡಲು ಸರ್ಕಾರ ನಿರ್ಧರಿಸ@@ ಿದೆ .\n",
+ "ವಿ@@ ಮಾನ ನಿ@@ ಲ್@@ ದಾ@@ ಣ@@ ದಲ್ಲಿ ಕೈ@@ ಬಿಡ@@ ಲಾದ ಸರ@@ ಕು@@ ಗಳನ್ನು ನಿರ್ವಹ@@ ಿಸುವಲ್ಲಿ ಸಮಸ್ಯೆ ಇದೆ .\n",
+ "ಶಿ@@ ಥ@@ ಿ@@ ಲ@@ ಗೊಂಡ ಕಟ್ಟಡ@@ ಗಳ ತ್ಯ@@ ಜ@@ ಿಸುವ ಪ್ರಕ್ರಿಯ@@ ೆಯನ್ನು ಎ@@ ಸ್ಟ@@ ೇಟ್ ಇಲಾಖೆ ಆರಂಭ@@ ಿಸಿದೆ .\n",
+ "ಮಾ@@ ಲಿ@@ ನ್ಯ@@ ವನ್ನು ಕೊ@@ ನ@@ ೆಗೊಳ@@ ಿಸಲು ಕೈಗೊಳ್ಳ@@ ಬೇಕು .\n",
+ "ಸರ್ಕಾರವು ಆ@@ ಮ@@ ದು ಸು@@ ಂಕ@@ ವನ್ನು ಕಡಿಮೆ ಮಾಡಲು ಕ್ರಮಗಳನ್ನು ತೆಗೆದುಕೊಳ್ಳ@@ ುತ್ತಿದೆ .\n",
+ "ಕಾನೂ@@ ನಿ@@ ನ ಈ ವಿಭಾಗ@@ ವನ್ನು ರ@@ ದ್ದ@@ ು@@ ಗೊಳಿಸಲಾಗಿದೆ .\n",
+ "ಸರ್ಕಾರಿ ಮನೆ@@ ಗಳ ಬಾ@@ ಡ@@ ಿಗೆ ಕಡ@@ ಿತ@@ ದ ಪ್ರಸ್ತಾ@@ ವ@@ ನೆ ಪರಿ@@ ಶೀ@@ ಲನ@@ ೆಯಲ್ಲ@@ ಿದೆ .\n",
+ "ಪ್ರ@@ ಯಾ@@ ಣ@@ ಿಕ ಸಾ@@ ರಿಗ@@ ೆಗೆ 60 % ರಿಯಾ@@ ಯ@@ ಿತ@@ ಿಯ@@ ೊಂದಿಗೆ 1@@ 2.@@ 3@@ 6 % ದ@@ ರದಲ್ಲಿ ತೆ@@ ರಿಗೆ ವಿಧ@@ ಿಸಲಾಗುತ್ತದೆ .\n"
+ ]
+ }
+ ],
+ "source": [
+ "! head -n 10 train.kn"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "39V10nlIUXT9",
+ "outputId": "460dadc6-6551-4141-a30f-cdd3a46e2880"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "एस@@ ई@@ सी@@ एल को बा@@ ढ़ प्रभावित को@@ य@@ ला ख@@ दा@@ नों को छोड़@@ ना पड़ा ।\n",
+ "वित्@@ त मंत्रालय ने अपने राज@@ स्@@ व संबंधी छो@@ ड़े हुए दा@@ वे को नए सि@@ रे से पे@@ श करने का निर्णय लिया है ।\n",
+ "सरकार ने कंपनी की छो@@ ड़ी हुई परि@@ सं@@ पत्@@ तियों की नी@@ ला@@ मी का फै@@ स@@ ला किया है ।\n",
+ "वि@@ मान पत्@@ तन में छो@@ ड़े हुए कार्@@ ग@@ ो को रखने की समस्या आ रही है ।\n",
+ "सं@@ प@@ दा विभाग द्वारा ज@@ र्@@ जर भ@@ व@@ नों को छोड़@@ ने की प्रक्रिया शुरू की गई ।\n",
+ "प्र@@ दू@@ षण समाप्त करने के लिए कदम उठा@@ ने हैं ।\n",
+ "सरकार आ@@ या@@ त शु@@ ल्@@ क कम करने के लिए कदम उठ@@ ा रही है ।\n",
+ "कान@@ ून की इस धार@@ ा का उप@@ श@@ मन हो चु@@ का है ।\n",
+ "सरकारी आवा@@ सों के कि@@ रा@@ ये में कमी का प्रस्ताव वि@@ च@@ ारा@@ ध@@ ीन है ।\n",
+ "या@@ त्र@@ ी परि@@ वहन पर 60 % की छू@@ ट के साथ 1@@ 2.@@ 3@@ 6 % की दर से कर व@@ सू@@ ला जाता है ।\n"
+ ]
+ }
+ ],
+ "source": [
+ "! head -n 10 train.hi"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "\n",
+ "# Starting NMT Training\n",
+ "## Preprocessing stage ; create dictionaries, make corpora ready for parallel processing\n"
+ ],
+ "metadata": {
+ "id": "fuZl-vwLjqy8"
+ }
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "!pip install torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 configargparse\n",
+ "\n",
+ "!python OpenNMT-py/preprocess.py \\\n",
+ "\t -train_src train.kn \\\n",
+ "\t -train_tgt train.hi \\\n",
+ "\t -valid_src valid.kn \\\n",
+ "\t -valid_tgt valid.hi \\\n",
+ "\t -save_data processed -share_vocab -overwrite"
+ ],
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "7dNw2BuMbzlg",
+ "outputId": "cb4cef54-875e-4a9d-cf2e-15e9ef7e7edd"
+ },
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Requirement already satisfied: torch==1.13.1 in /usr/local/lib/python3.10/dist-packages (1.13.1)\n",
+ "Requirement already satisfied: torchvision==0.14.1 in /usr/local/lib/python3.10/dist-packages (0.14.1)\n",
+ "Requirement already satisfied: torchaudio==0.13.1 in /usr/local/lib/python3.10/dist-packages (0.13.1)\n",
+ "Collecting configargparse\n",
+ " Obtaining dependency information for configargparse from https://files.pythonhosted.org/packages/6f/b3/b4ac838711fd74a2b4e6f746703cf9dd2cf5462d17dac07e349234e21b97/ConfigArgParse-1.7-py3-none-any.whl.metadata\n",
+ " Downloading ConfigArgParse-1.7-py3-none-any.whl.metadata (23 kB)\n",
+ "Requirement already satisfied: typing-extensions in /usr/local/lib/python3.10/dist-packages (from torch==1.13.1) (4.5.0)\n",
+ "Requirement already satisfied: nvidia-cuda-runtime-cu11==11.7.99 in /usr/local/lib/python3.10/dist-packages (from torch==1.13.1) (11.7.99)\n",
+ "Requirement already satisfied: nvidia-cudnn-cu11==8.5.0.96 in /usr/local/lib/python3.10/dist-packages (from torch==1.13.1) (8.5.0.96)\n",
+ "Requirement already satisfied: nvidia-cublas-cu11==11.10.3.66 in /usr/local/lib/python3.10/dist-packages (from torch==1.13.1) (11.10.3.66)\n",
+ "Requirement already satisfied: nvidia-cuda-nvrtc-cu11==11.7.99 in /usr/local/lib/python3.10/dist-packages (from torch==1.13.1) (11.7.99)\n",
+ "Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from torchvision==0.14.1) (1.23.5)\n",
+ "Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from torchvision==0.14.1) (2.31.0)\n",
+ "Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /usr/local/lib/python3.10/dist-packages (from torchvision==0.14.1) (9.4.0)\n",
+ "Requirement already satisfied: setuptools in /usr/local/lib/python3.10/dist-packages (from nvidia-cublas-cu11==11.10.3.66->torch==1.13.1) (67.7.2)\n",
+ "Requirement already satisfied: wheel in /usr/local/lib/python3.10/dist-packages (from nvidia-cublas-cu11==11.10.3.66->torch==1.13.1) (0.41.2)\n",
+ "Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->torchvision==0.14.1) (3.2.0)\n",
+ "Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->torchvision==0.14.1) (3.4)\n",
+ "Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->torchvision==0.14.1) (2.0.4)\n",
+ "Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->torchvision==0.14.1) (2023.7.22)\n",
+ "Downloading ConfigArgParse-1.7-py3-none-any.whl (25 kB)\n",
+ "Installing collected packages: configargparse\n",
+ "Successfully installed configargparse-1.7\n",
+ "\u001b[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\u001b[0m\u001b[33m\n",
+ "\u001b[0m[2023-09-23 05:40:19,687 INFO] Extracting features...\n",
+ "[2023-09-23 05:40:19,690 INFO] * number of source features: 1.\n",
+ "[2023-09-23 05:40:19,690 INFO] * number of target features: 0.\n",
+ "[2023-09-23 05:40:19,690 INFO] Building `Fields` object...\n",
+ "[2023-09-23 05:40:19,691 INFO] Building & saving training data...\n",
+ "[2023-09-23 05:40:19,870 INFO] Building shard 0.\n",
+ "[2023-09-23 05:40:21,946 INFO] * saving 0th train data shard to processed.train.0.pt.\n",
+ "[2023-09-23 05:40:24,031 INFO] * tgt vocab size: 2488.\n",
+ "[2023-09-23 05:40:24,038 INFO] * src vocab size: 2956.\n",
+ "[2023-09-23 05:40:24,039 INFO] * src_feat_0 vocab size: 39.\n",
+ "[2023-09-23 05:40:24,039 INFO] * merging src and tgt vocab...\n",
+ "[2023-09-23 05:40:24,057 INFO] * merged vocab size: 5306.\n",
+ "[2023-09-23 05:40:24,091 INFO] Building & saving validation data...\n",
+ "[2023-09-23 05:40:24,142 INFO] Building shard 0.\n",
+ "[2023-09-23 05:40:24,258 INFO] * saving 0th valid data shard to processed.valid.0.pt.\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "_F8k7167up78"
+ },
+ "outputs": [],
+ "source": [
+ "ls data-bin/trial"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [],
+ "metadata": {
+ "id": "IwZtWm12DXqF"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "# Training\n",
+ "## Parameters to fix for your corpora and language pair\n",
+ "\n",
+ "\n",
+ "\n",
+ "```\n",
+ " --encoder-embed-dim\t128 --encoder-ffn-embed-dim\t128 \\\n",
+ " --encoder-layers\t2 --encoder-attention-heads\t2 \\\n",
+ " --decoder-embed-dim\t128 --decoder-ffn-embed-dim\t128 \\\n",
+ " --decoder-layers\t2 --decoder-attention-heads\t2 \\\n",
+ " --dropout 0.3 --weight-decay 0.0 \\\n",
+ " --max-update 4000 \\\n",
+ " --keep-last-epochs\t10 \\\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "---\n",
+ "\n"
+ ],
+ "metadata": {
+ "id": "ThmR6CUikOCr"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "RonQ8-I1yaPB"
+ },
+ "outputs": [],
+ "source": [
+ "! python OpenNMT-py/train.py -data processed -save_model model.pt \\\n",
+ "\t\t-layers 6 -rnn_size 512 -src_word_vec_size 512 -tgt_word_vec_size 512 -transformer_ff 2048 -heads 8 \\\n",
+ "\t\t-encoder_type transformer -decoder_type transformer -position_encoding \\\n",
+ "\t\t-train_steps 200000 -max_generator_batches 2 -dropout 0.1 \\\n",
+ "\t\t-batch_size 4096 -batch_type tokens -normalization tokens -accum_count 2 \\\n",
+ "\t\t-optim adam -adam_beta2 0.998 -decay_method noam -warmup_steps 8000 -learning_rate 2 \\\n",
+ "\t\t-max_grad_norm 0 -param_init 0 -param_init_glorot \\\n",
+ "\t\t-label_smoothing 0.1 -valid_steps 10000 -save_checkpoint_steps 10000 \\\n",
+ "\t\t-world_size 1 -gpu_ranks 0"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "TPU",
+ "colab": {
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/training-code/README.md b/training-code/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..bef71c80db38b932e57226cc509e637fa89ff0b0
--- /dev/null
+++ b/training-code/README.md
@@ -0,0 +1,16 @@
+# Training Code Script
+
+## Code
+1. lndian_language_to_indian_language_machine_transaltion_iiith_2023_v1_5.py
+2. Lndian_Language_to_Indian_Language_Machine_Transaltion_IIITH_2023_v1_5.ipynb (comments are given; also please use your data for training)
+
+
+## Colab version
+
+1. https://colab.research.google.com/drive/1jHXH6lBQZTkptC3MMb1O880draZL3dfy?usp=sharing
+
+## Training Data
+1. https://ssmt.iiit.ac.in/meitygit/palash/himangy-corpora
+2. https://ai4bharat.iitm.ac.in/bpcc
+3. https://ssmt.iiit.ac.in/meitygit/root/Hindi-Telugu-Data
+4. https://ssmt.iiit.ac.in/meitygit/root/PSA-DATA-NLTM
diff --git a/training-code/lndian_language_to_indian_language_machine_transaltion_iiith_2023_v1_5.py b/training-code/lndian_language_to_indian_language_machine_transaltion_iiith_2023_v1_5.py
new file mode 100644
index 0000000000000000000000000000000000000000..aaed1107c466691cc6b59b2462d7d5854043eb3b
--- /dev/null
+++ b/training-code/lndian_language_to_indian_language_machine_transaltion_iiith_2023_v1_5.py
@@ -0,0 +1,192 @@
+# -*- coding: utf-8 -*-
+"""Lndian Language to Indian Language Machine Transaltion-IIITH-2023-v1.5.ipynb
+
+Automatically generated by Colaboratory.
+
+Original file is located at
+ https://colab.research.google.com/drive/1jHXH6lBQZTkptC3MMb1O880draZL3dfy
+
+# ** Hybrid Neural Machine Translation for HimangiY **
+#### Vandan Mujadia, Dipti Misra Sharma
+#### LTRC, IIIT-Hyderabad, Hyderabad
+
+This demonstrates how to train a sequence-to-sequence (seq2seq) model for Kannada-to-Hindi translation **roughly** based on [Effective Approaches to Attention-based Neural Machine Translation](https://arxiv.org/abs/1706.03762) (Vaswani, Ashish et al).
+
+## An Example to Understand sequence to Sequence processing using Transformar Network.
+
+ +
+Source: [Google AI Blog](https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html)
+
+## Applying the Transformer to machine translation.
+
+
+
+
+Source: [Google AI Blog](https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html)
+
+## Applying the Transformer to machine translation.
+
+
+
+
+
+ 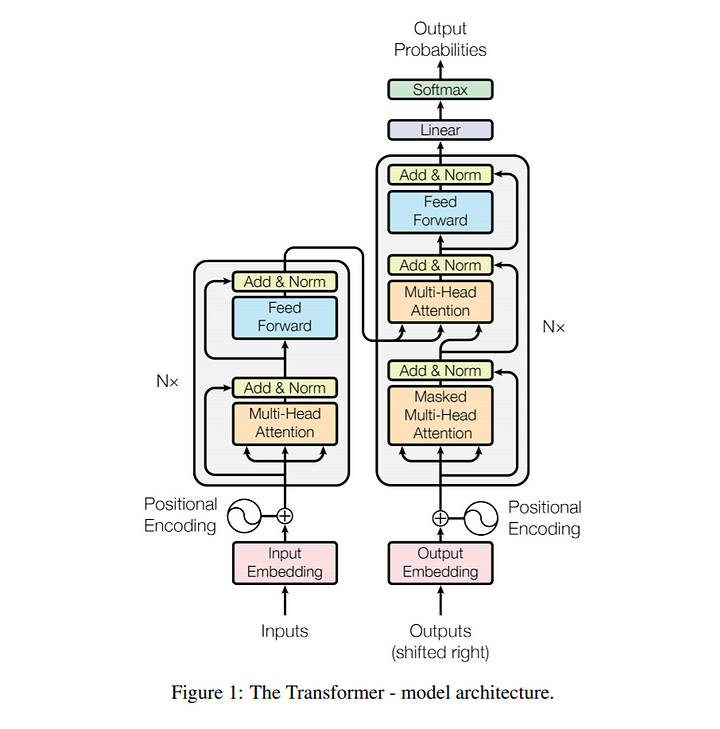 +
+ |
+
+
+ | This tutorial: An encoder/decoder connected by self attention neural network. |
+
+
+
+# Tools that we are using here
+
+* Library : Opennmt
+* Library : pytorch based neural network implemtation
+"""
+
+# Commented out IPython magic to ensure Python compatibility.
+!pip install -U pip
+!!git clone https://github.com/OpenNMT/OpenNMT-py
+! ls
+# %cd OpenNMT-py
+!git checkout 1.2.0
+!pip3 install torchtext==0.4.0 torch==1.11.0
+
+# Commented out IPython magic to ensure Python compatibility.
+# %cd /content/
+
+"""# Check GPU"""
+
+!nvidia-smi
+
+"""# Tokenizer Tool"""
+
+!pip install git+https://github.com/vmujadia/tokenizer.git --upgrade
+
+"""# To Clean and Filter Parallel Corpora"""
+
+!git clone https://github.com/moses-smt/mosesdecoder.git
+
+"""# To tackle vocabulary issue : Subword algorithm"""
+
+!git clone https://github.com/rsennrich/subword-nmt.git
+
+!ls mosesdecoder/scripts/training/clean-corpus-n.perl
+
+"""# For this; Training Corpora
+
+## Kannada - Hindi
+## (small courpus MIT+CDAC-B developed)
+"""
+
+! wget -O train.src https://ssmt.iiit.ac.in/uploads/data_mining/kannada-hindi_combined_all.hi
+! wget -O train.tgt https://ssmt.iiit.ac.in/uploads/data_mining/kannada-hindi_combined_all.kn
+! wget -O valid.src https://ssmt.iiit.ac.in/uploads/data_mining/flores200-dev.hi
+! wget -O valid.tgt https://ssmt.iiit.ac.in/uploads/data_mining/flores200-dev.kn
+
+"""# Data Numbers"""
+
+print ('Data Stats')
+! wc -l train.*
+! wc -l valid.*
+
+"""# Tokenize the text"""
+
+from ilstokenizer import tokenizer
+import codecs
+
+def to_tokenize_and_lower(input_path, output_path):
+ outfile = open(output_path, 'w')
+ for line in codecs.open(input_path):
+ line = line.strip()
+ line = tokenizer.tokenize(line).lower()
+ #print (line)
+ outfile.write(line+'\n')
+ outfile.close()
+
+to_tokenize_and_lower('train.src','train.src.tkn')
+to_tokenize_and_lower('train.tgt','train.tgt.tkn')
+
+to_tokenize_and_lower('valid.src','valid.src.tkn')
+to_tokenize_and_lower('valid.tgt','valid.tgt.tkn')
+
+! cat train.src.tkn > train.all.tkn
+! cat train.tgt.tkn >> train.all.tkn
+
+"""# Data Cleaning"""
+
+! perl mosesdecoder/scripts/training/clean-corpus-n.perl -ratio 2.5 train src.tkn tgt.tkn train_filtered 1 250
+
+print ('Data Stats')
+! wc -l train*
+! wc -l valid*
+
+print ('Data Stats')
+! wc -l train*
+! wc -l valid*
+
+"""# Train subword model,
+## Experiment with no of subword merge operation
+"""
+
+!python subword-nmt/subword_nmt/learn_bpe.py -s 5000 < train.all.tkn > train.codes
+
+"""# How do subword codes look"""
+
+! head -n 10 train.codes
+
+"""# Apply Subword to the corpus"""
+
+!python subword-nmt/subword_nmt/apply_bpe.py -c train.codes < train.src > train.kn
+!python subword-nmt/subword_nmt/apply_bpe.py -c train.codes < train.tgt > train.hi
+
+!python subword-nmt/subword_nmt/apply_bpe.py -c train.codes < valid.src > valid.kn
+!python subword-nmt/subword_nmt/apply_bpe.py -c train.codes < valid.tgt > valid.hi
+
+"""# Training Corpus now"""
+
+! head -n 10 train.kn
+
+! head -n 10 train.hi
+
+"""
+# Starting NMT Training
+## Preprocessing stage ; create dictionaries, make corpora ready for parallel processing
+"""
+
+!pip install torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 configargparse
+
+!python OpenNMT-py/preprocess.py \
+ -train_src train.kn \
+ -train_tgt train.hi \
+ -valid_src valid.kn \
+ -valid_tgt valid.hi \
+ -save_data processed -share_vocab -overwrite
+
+ls data-bin/trial
+
+"""# Training
+## Parameters to fix for your corpora and language pair
+
+
+
+```
+ --encoder-embed-dim 128 --encoder-ffn-embed-dim 128 \
+ --encoder-layers 2 --encoder-attention-heads 2 \
+ --decoder-embed-dim 128 --decoder-ffn-embed-dim 128 \
+ --decoder-layers 2 --decoder-attention-heads 2 \
+ --dropout 0.3 --weight-decay 0.0 \
+ --max-update 4000 \
+ --keep-last-epochs 10 \
+```
+
+
+
+---
+
+
+"""
+
+! python OpenNMT-py/train.py -data processed -save_model model.pt \
+ -layers 6 -rnn_size 512 -src_word_vec_size 512 -tgt_word_vec_size 512 -transformer_ff 2048 -heads 8 \
+ -encoder_type transformer -decoder_type transformer -position_encoding \
+ -train_steps 200000 -max_generator_batches 2 -dropout 0.1 \
+ -batch_size 4096 -batch_type tokens -normalization tokens -accum_count 2 \
+ -optim adam -adam_beta2 0.998 -decay_method noam -warmup_steps 8000 -learning_rate 2 \
+ -max_grad_norm 0 -param_init 0 -param_init_glorot \
+ -label_smoothing 0.1 -valid_steps 10000 -save_checkpoint_steps 10000 \
+ -world_size 1 -gpu_ranks 0
\ No newline at end of file